I once helped a company that its core product was relying on high resolution images, and each page load on its website and mobile apps loaded 60-100 images easily in a single page request. Thinking like Pinterest or Instagram as users browsed the service, the volume of these requests would be staggering and having a performant service infrastructure to serve images directly impacted user experience and revenue. In this article I will show you my first journey with scaling the existing architecture, lessons learned, and lay out the path for a future design that would auto-scale for good.
Please note that as a security cautious leader, I have left out details pertaining the security controls existing in this infrastructure architecture and nothing I share here reveals any secret sauce relating to that.
Background
Since the bread and butter of this business is based on images that its users upload to its service, the durability of its storage is a must have criteria. Second to that is performance and availability of its service because just a single thumbnail loading slow or not loading on a page negatively impacts the user experience. Upon taking over this project, it was quickly realized that at the current user upload rate, the existing image cluster would run out of space in less than 2 months. It is 2014 and nobody should be worried about space issues any more with the advancements in public cloud technologies like Amazon S3, but unfortunately the infrastructure in reference was not hosted on the cloud and it was hosted by a data center managed service provider, hence it came with its own challenges of scaling.
Current Architecture
Before we dive into problems and solutions, let’s understand how the existing infrastructure architecture works and what problems we are facing.
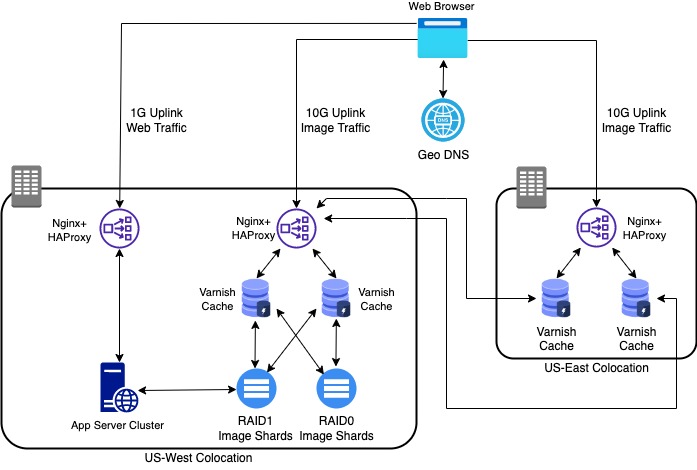
There are two managed date center colocations in this architecture as depicted in Figure 1. The one on the left is the primary data center that hosts everything from application servers, backend databases, caching servers, search indexes, and image servers. For the purpose of focusing on image service, the diagram is only showing components that involve storing and serving images, and all other components have been left out. The data center on the right only hosts a caching layer which uses the primary data center as its origin backend. You can think of this being like a CDN point of presence or POP. The reason for this multi region architecture is performance as this company served the entire north America at the time.
Multi-Tiered Service Architecture
Since browsers can handle a limited number of simultaneous requests to a domain, the domain that served the web page was the primary domain like www.mywebsite.com, and a separate static domain was used to server the images like st.mywebsite.com. The static domain is also a cookie-less domain meaning the request and responses don’t carry out any cookie payload. This is a micro-optimization tactic which is the best practice for static services to keep the request payloads low as cookies can be as large as 4KB in size and usually trigger server side processing.
The client browser first sends the page load request to the primary domain which is hosted by the US-East colocation only and receives the HTML back. Then the browser parses the HTML and detects images coming from a separate static domain, and starts to asynchronously fetch them 10 at a time. The static domain is configured via a Geo DNS service like Dyn. It resolves the domain to an IP address pointing at either US-West colocation or US-East colocation based on the proximity of the user to each location for faster connection establishment and date transfer rate.
Inside each colocation there is an active-passive pair of Nginx+HAProxy load balancers that terminates the connection and routes the request to the appropriate cache backend. At the time HAProxy didn’t have TLS support, and a common load balancing stack used Nginx for TLS termination and HAProxy for its core competency which is load balancing. Varnish was used for caching images and assets like JS/CSS, and there were two clusters of two super high memory machines in each colocation (total of four boxes) and each cluster was responsible for either static sized images or dynamic sized images with failover setup between the two clusters. Unfortunately US-West was the only colocation with the source images residing on separate image servers, so US-East didn’t really have its own image source origin backend and instead used the US-West as its origin backend. This is actually how most CDNs work when the source origin is in one place, however, that one place is a huge risk if it comes to the colocation getting hit by a disaster.
The cache servers used a cluster of machines with large volumed disks in RAID1 and RAID0 format as their backend origin. This is where the actual image files were stored. Since there were 10s of terabytes of images, vertically scaling the image servers was not a scalable option, so a sharding strategy was implemented to distribute the images horizontally among multiple active-active pairs of boxes. I will discuss how this logic was done in the next section. Varnish configuration was programmed to serve the images from its cache upon hit and was able to detect which image shard to go to as its backend origin in case of the miss.
Consistent Hashing Strategy for a Horizontally Distributed Storage
The images are uploaded from the client browser through the load balancer to the application server. The application service uses a consistent hashing strategy to determine which image cluster shard the image would fall into as well as creating multiple resized thumbnails of the image.
Here is an example:
An image file is uploaded. To avoid collision in hashing based on the image file name, owner username, and upload timestamp was appended to the file name and then a SHA1 checksum of the resulting string was computed (We are not going to talk about SHA1 collision probability here as it is too low. You can nerd about it from this Google blog post). To determine which shard the image falls into, she first 4 characters of the resulting hash was taken as it was used as the shard token for that image.
We call this a consistent hashing strategy because the resulting shard token will be based on the file name and is consistently producible by the same algorithm.
2
3
file_name_hash = sha1(original_file_name + username + time_microsecond)
shard_token = file_name_hash.substr(0, 4)
The file_name_hash was used as the image metadata in the application database and that is what was rendered in the image URL along with some metadata appended for SEO optimization, and shard_token was used to map the file name for upload to a specific pair of image machines. Before we get to the shard token, let’s see how the token range is defined and assigned to each machine. Since SHA1 produces a string with hexadecimal characters, taking the first 4 bytes of the string as the token, will give us the following total token range:
2
bucket_size = ffff / 32 = 51e
Now assume we have 32 pairs of image machine which translates to 32 image shards. To evenly distribute the image load, we need to divide this range to 32 equal buckets and assign each bucket to a pair of machines. The upper bound of bucket range was stored in the application server configuration as the hash key so that when the image is uploaded, the application server can take the shard token, and iterate over token ranges performing an arithmetic comparison against token upper bounds to determine which image server to copy it to:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
"051e" => Array("images-m-01.internal_dns", "images-s-01.internal_dns"),
"0a3c" => Array("images-m-02.internal_dns", "images-s-02.internal_dns"),
"0f5a" => Array("images-m-03.internal_dns", "images-s-03.internal_dns"),
...
...
"fae1" => Array("images-m-31.internal_dns", "images-s-31.internal_dns"),
"ffff" => Array("images-m-32.internal_dns", "images-s-32.internal_dns")
}
foreach(image_cluster_map.keys() as token) {
if (shard_token < token) {
return image_cluster_token_map[token];
}
}
The above consistent hashing sharding strategy can be easily implemented on the Varnish cache servers where the input would be the image URL that has the file_name_hash, and therefore the origin image cluster can be identified upon cache miss by performing the same arithmetic logic in Varnish VCL.
Problems
As you have digested the above architecture, you can easily spot multiple challenges with it:
- Durability: even though there are pairs of image servers, and durability exists against one machine failing, they all resided in one colocation. If this colocation gets hit by a disaster, the entire business is gone as there was no business continuity plan or backup in place.
- Performance: if any of the Varnish nodes went down, there would be a hotspot in the other Varnish node likely resulting in the LRU cache to evict objects quicker and lowering cache hit rate and reduce performance of service as a result.
- Scalability: This architecture is definitely not at web-scale. The company was planning for a large international expansion at the time, so there was no way to easily move fast and setup more POPs to serve international traffic with the desired performance SLA.
- Expensive Infrastructure: each POP costed thousands of dollars per month to maintain, specially the 10G uplinks that aren’t cheap.
- High Maintenance Cost: the image shard running out of space is a big issue specially when it is relative to user upload volume which could grow fast out of our control. So, you always have to think ahead and do capacity planning and plan to have enough head room to allow for unprecedented growth. And as you see from the architecture, to avoid hotspots, each time we want to scale the image shards we have to double the capacity to evenly distribute the load avoiding re-tokenization and balancing which is an expensive operation in distributed systems like this.
Solutions
Time was a huge factor since the cluster would run out of space in 2 months. So, I had to evaluate multiple options with their pros and cons:
- Move to the cloud: the ideal option would be to replace this entire setup with AWS, leveraging S3, a few EC2 machines in auto-scaling mode to perform the dynamic resizing, and use a CDN in front. This would be my ultimate solution for good. At the time, there were a lot of beliefs existed in the team that S3 and cloud solutions aren’t performance and cost effective. I was the only cloud guy in the team, so I had no time to experiment with a POC and do performance testing to demystify these beliefs.
- Replace the architecture with a scalable storage solution: instead of scaling the existing setup, I could have replaced it with another system like Ceph. This could have been a good solution for keeping things running in the data center and abstract out the storage and eliminate all of these manual sharding strategies. However, at this time, Ceph was just open sourced by the Dreamhost team who built it, so there was a risk with adopting a new open source component, and since this required architecture changes that are not battle tested with our workload, I had to undergo a massive re-architecture and load testing to make sure it can deliver the same performance SLAs. Two months seemed short, so the risk was high.
- Scale the current architecture by doubling its capacity: since this architecture was proven to be performant to service the entire north America market, I could confidently say that I don’t need to perform rigorous performance testing, and I just need to double the number of image shards. My only bottleneck was whether the managed data center provider can give me more servers fast enough so that I can perform the migration on time before I approach the two months timeframe.
Scaling the Current Architecture by Doubling its Capacity
Here is the step by step plan of execution for this strategy:
- Define hardware spec and order it through the managed date center provider in US-West region
- Setup the servers using the configuration management tool which was Saltstack at the time
- Implement dual-write strategy in the application so new images are copied to both existing and new shards
- Run a migration script asynchronously to copy half of the images based on splitting the token range from old machine to the new machines
- Change Varnish cache to use all 64 image machines
- Cleanup old servers and remove half of their load which was moved to new servers
Normally when you order hardware, depending on what hardware architecture like chassis and CPU that you order and the status of supply chain, it could take anywhere from 2-6 weeks for them to arrive at the colocation. I just hoped that this timeline is closer to 2 weeks rather than 6. Luckily the image servers where simple 1U blades, with Xeon E3 processors, and Hitachi hard drives. This was the bare bone server architecture used for all general purpose application workloads. You can think of them being like M class in AWS EC2. Therefore, the data center folks, since they run their own cloud business too, had a lot of these servers in stock and ready to repurpose. My only additional requirement was the RAID controller and extra Hitachi drives to give more storage capacity to each box. So, I asked them to setup 32 more boxes with 16 being on rack A and another 16 being on rack B where other image boxes lived. Each rack had its own switch and separate power source so at least we’d get power and network redundancy in the single colocation. It took two weeks for the machines to get ready for provisioning.
Saltstack was used to automate provisioning of the machines and configure each box with necessary services. Next step was to assign new token ranges to each box and implement a dual write strategy for new uploads as part of the phase 1 of this migration.
Phase I – Splitting Token Ranges and Dual Writing Strategy
In order to evenly distribute the load of existing boxes, we must have split the token ranges that they are responsible for. This is why we doubled the number of shards from 32 to 64 for the total of 128 servers.
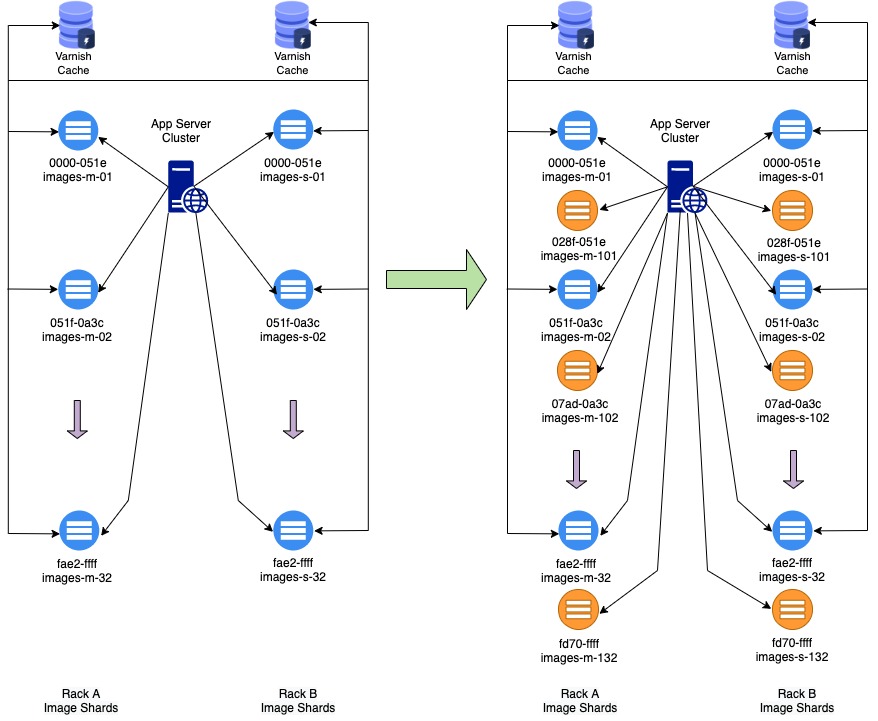
In the original setup, there were a total of 64 servers and 32 shards/buckets. The pairs were setup in different racks with different power source and network sources for redundancy in the local colocation. The size of each server’s bucket was 0x051e. Varnish cache nodes were reading from all servers and application servers were also copying newly uploaded images to the server pair which owned the token range for those images. This is depicted in Figure 2 on the left.
The right side of Figure 2 shows the new architecture. We added a new pair of server for each existing pair that claimed half of the token ranges of the existing server pair. This means we split the initial token range of 0x051e by half which comes out to 0x028f. So taking the first pair of servers, if the token range used to be 0x0000-0x051e, the new token range for them would become 0x0000-0x028e and the newly added server pair would claim 0x028f-0x051e. However, the newly setup servers would not have all the images for their token range until the asynchronous process syncs them all over. Therefore, the token range of the existing servers in this phase remains untouched. We just add a new token range configuration in the application server for the new servers, so they get a copy of recently uploaded images after this configuration was setup. This defines our dual-write strategy. Additionally, Varnish cache servers are still only reading from the old server pairs until we confirm synchronization process is done.
At this stage we also kick off a script that runs on one of the servers on each pair which lookups up for images that belonged to the new shard, and copies them over. We also use I/O throttling flags in rsync to avoid slowness in service upon cache missed on Varnish.
We need to wait for all syncs between old and new servers to complete, before we move to the next phase. This process for the images took 2 weeks to complete.
The metrics to monitor in this phase are:
- Cache Miss Request Latency: this value is going to increase a bit because our copying process is taking a lot of I/O bandwidth, but if it increases drastically to a point that service SLAs are impacted, then you’d want to think about strategies to isolate the slowness. In our scenario, we used rsync’s throttling mechanism to slow down our process.
Phase II – Reconfigure Token Map
At this point, the new servers have the full copy of the images that they are responsible for serving based on their token map. The old servers however, still have the extra half which we will cleanup after there are no issues in the traffic.
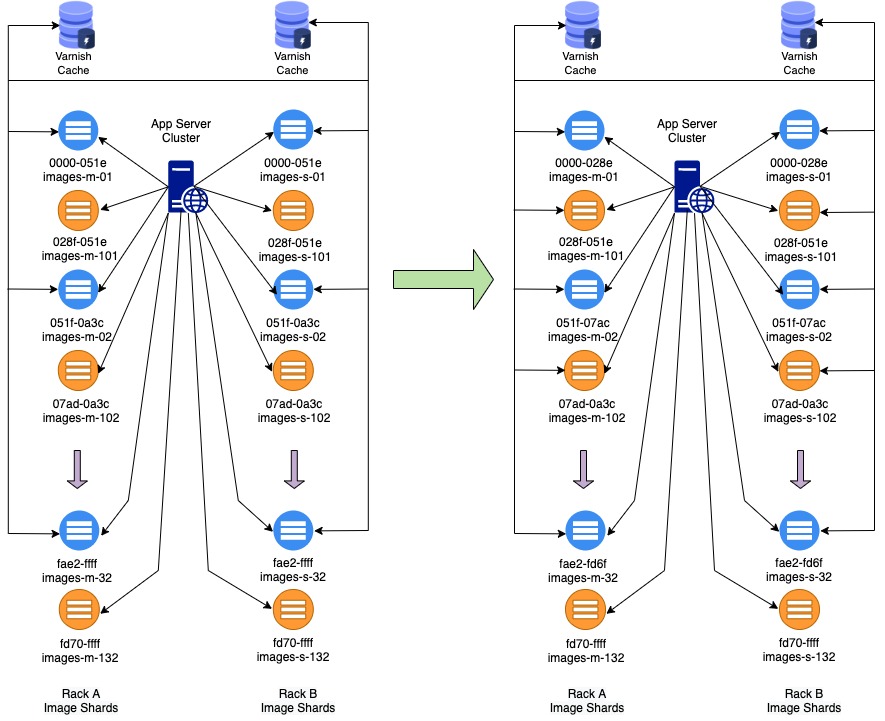
In this stage, we want to remove the dual write mechanism from app servers to both old and new image server pairs. We simply do this by reconfiguring the token map assigned to each server pair to only own their equal share of tokens. At this stage we also reconfigure Varnish cache nodes logic to handle the new token map and use all server pairs as backends.
Good metrics to monitor to ensure everything is good in this setup are:
- Cache Hit Ratio: this metric should not be affected as we only changed the origin backend.
- Cache Miss Request Latency: this is the latency for loading images from origin server pairs. Since we doubled the capacity, the latency should be decreased since I/O should be less stressed. This metric is a proxy for I/O performance, but if we desired to drill down, we could also look at disk I/O latency which could have gone down since each disks load is split by half.
- Cache Miss Request Status: this is the HTTP status code of the requests being sent to the origin server pairs. If everything is copied fine and the configuration maps are correct, there should not be any increase on 404 Not Found status codes unless the requested file name is bogus. If this increases, it could mean that some files are missing or the token map configuration is not sending requests to the right server pair.
Phase III – Cleanup
For the cleanup, we just executed a script that deleted the files that were moved to the new servers and were no longer belonging to the old server’s token range. In this phase, we also used strategies to throttle I/O. Since Linux rm command doesn’t come up with its own throttling flag, we used ionice to throttle the disk I/O.
Conclusion and Next Steps
Time and service continuity was the biggest influencer in implementing this scaling strategy. The solution, gave us enough headroom to operate for a few more months, while we strategize around moving this to the cloud for good. The performance of this architecture was good enough to meet the maximum of 150ms object load time, but that performance goal is based solely on serving North America region and not the entire world. We learned that how difficult is it to scale this cluster and why it won’t work for the long run. All other problems remained unsolved until we move this to the cloud as the next step.