Table of Contents
Introduction
In a startup company, during the early days you should hire full-stack engineers who are willing to learn and do anything to keep your cost low. This means that at some point an engineer is asked to setup data ingestion pipelines and BI tools so that your product team can make data-driven decisions. As your organization scales, the need to make data-driven decisions will not be limited to only product decisions. Other stakeholders such as CFO and CEO would want to look at financial metrics regularly. A mistake I have seen a CEO make early on is to segregate analysis of financial data in silos or ask each executive running a functional organization to do it their own way, and I have worked at organizations that hire folks who are Excel crunchers and not necessarily BI experts. This creates fragmentation in the organization at the cost of increased headcount, fragmentation in tools that increase cost of maintenance, and debates on what is the source of truth. And when you want to ask questions that pertain correlating data from both product metrics, financial data, and others, the solutions fall short. For example, the financial analysts will have to do rigorous repeated work each month using Excell, and pull data from various sources such as ERP, LMS and other systems into presentation slides and then would be presented while an army of executives and middles managers sit in a room. Most of the time questions arising could be answered if the charts on presentation were interactive, but this cause chaos of having to go back and recreate and represent the presentation to address the questions. This is an absolute waste of time in an era of tools and systems that can give you a bird eye view of your business as well as giving you the ability to drill down without having to reproduce anything. While the engineer wants to setup data ingestion pipelines into a common data warehouse and build BI dashboards on top of it. The job of that full-stack engineer becomes difficult and beyond their original expertise fast.
Additionally in an age of AI where data is heavily used to train models and further produce data to train models even more, the semantics of data and how they are collected and quality controlled becomes essential. For example, if a company wants to use images to train deep learning models that detect and classify objects in an image, they need to first collect high resolution images, and secondly have a way to contextually tag images for the model training which involves human judgment at first. If the company didn’t specify standards on required image quality and how they are going to be tagged as part of their data strategy, it will impact whether this feature can be created or not. Therefore, it is not prudent to not think about how to solve these problems early on in your organization.
In today’s data-driven world, organizations across industries are realizing the paramount importance of a well-defined data strategy. A robust data strategy can drive business growth, enhance decision-making, and ensure a competitive edge for the long term. In this article, we will explore what a data strategy is, delve into various data strategies, examine metrics for different teams and stakeholders, explore data team structures, tools, roles, and provide solutions for implementing a successful data strategy.
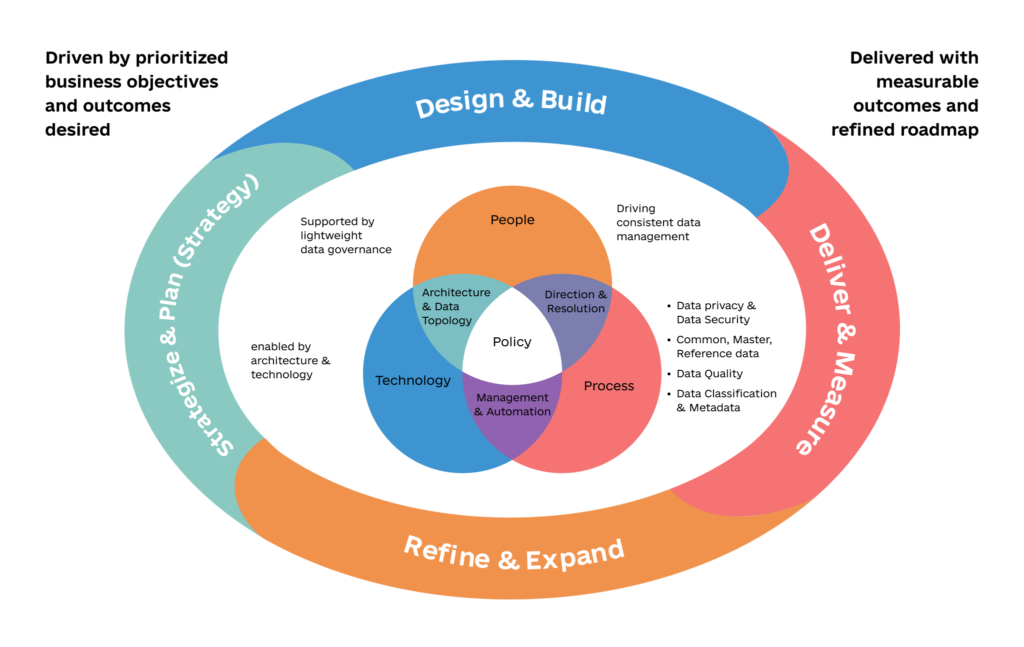
Understanding Data Strategy
A data strategy is a comprehsive plan that outlines how an organization will collect, store, manage, and leverage data to achieve its objectives. It encompasses a variety of components, including data governance, data architecture, data management, and analytics. An effective data strategy is tailored to an organization’s specific needs, aligns with its goals, and considers data as a valuable asset.
In the examples above, the chaos caused as a result of team and tools fragmentation is an outcome of not having a clear data strategy. A clear data strategy would have defined what data needs to be collected and in what way, and what roles needs to be involved in making it happen. For instance, it would have been wiser to hire a data engineer or at least a scrappy analytics engineer with experience working on data stacks to build a unified data warehouse. Additionally instead of hiring Excel experts, Data Analysts with BI expertises would have been more valuable assets.
Moreover, if the example company was interested to leverage data for machine learning and AI, a Data Scientist consultant could have been consulted on how to set the stage properly for future machine learning and AI needs if the senior leadership lacked those skills in their decision making.
These are all some of the problems that should have been solved as part of a clearly defined data strategy.
Different Data Strategies
Now that you have learned about the importance of data strategy with some examples, in this section we delve into what type of data strategy suites best for different problems with some examples that already exist out there.
Data Innovation Strategy
This strategy focuses on fostering a culture of innovation within the organization. It encourages experimentation, data-driven decision-making, and the development of data-driven products or solutions. Tech startups and forward-thinking enterprises often adopt this approach.
Data Driven Decision-Making
To implement this strategy, you should instill a culture of data-driven decision making throughout the organization, and employees should be trained how to understand, tell stories, and use data for decision making effectively. It is easy to observe if your organization lacks data-driven decision making by looking at the bottom line. If the overal performance of the organization is poor and declining, then this is a clear sign that data is not used properly to make decisions.
Experimentation
Another way to instill innovation with data is encourage your employees to run experiments. If you are a software organization and building a software product, A/B testing is the de-facto standard, and all successful companies like Google, Facebook, Airbnb, Houzz, and Dropbox have instilled a culture of experimentation. Even if experimentation leads to failure, know that innovation arises from learning and adapting. Failure is an opportunity to learn. When you observe in your team’s meetings that people debate on ideas and how to implement things with gut feelings and want to apply their experience, this is the best place to raise awareness and push for experimentation rather than gut feeling and past experiences which could certainly be biased. The experimentation is not solely limited to software but can also apply to hardware similarly as when scientists run lab tests on various pieces of hardware to understand their behavior.
Cross-Functional Collaboration
In developing a data strategy for innovation, the key element is cross-functional collaboration. Teams that operate in silos will miss opportunities that could result in discovery of solutions that could improve the overall quality of their product for their customers. Imagine in the very first example we had in this article about finance team being siloed fro product. Assume product team thinks building a certain feature would improve their product visibility and adoption of customers. They have done the qualitative research to proof what they want to build is something that customers want. However, they don’t have access to the operational cost metrics such as CAC or COGS. If the senior leadership does not see this shortcoming, the result could be catastrophic and company could end up making a product that users may like to use, but the cost of its operation doesn’t improve the bottom line and in fact burns money.
Tesla’s Data-Driven Autopilot system is an excellent example of an innovative data strategy. It collects data from their vehicles, including sensor readings, camera images, and driver behavior, to improve its self-driving capabilities. This data not only helps Tesla refine its autonomous driving systems, but also keeps their vehicles up-to-date with software.
Some lessons learned from Tesla’s story are:
- Innovation often relies on continuous data collection and analysis
- Real-world data is crucial for training machine learning models
- Safely and compliance are paramount when implementing data-driven innovations
Offensive Data Strategy
In building a data strategy, offensive data strategy is all about leveraging data to gain a competitive advantage. It includes using data analytics and insights to enhance customer experiences, develop new products, and improve operational efficiency. E-commerce, tech, and marketing companies often employ this approach.
Customer Insights
Every company must analyze its customer’s data to understand their behavior and preferences. These insights should then be used to improve customer service, personalized marketing, and develop tailored products. Almost every service we use today has one way of giving us recommendations and information personalized to our interest. And this is the most common pattern.
Operational Efficiency
The data may not only be used to improve customer products. It can be used to optimize internal operations by identifying bottlenecks, inefficiencies, and areas for improvement. Large companies like Google and Facebook have dedicated teams built around creating custom solutions to optimize their operation. At their scale, if a solution makes the cost of operation a little optimized for a single user, at a billion users scale, it can add up to millions in savings.
Competitive Intelligence
Data is used to gain insights into competitor’s strategies, merket trends, and emerging opportunities. When I worked in a consumable company, we used third-party data providers that gave us aggregated reports about which product categories and types are purchased by customers more. Additionally it gave us insights into market share of competitors. Using these two data points, we could identify patterns of interest by customers that may have not been captured by other competitors. And have the company focus on producing products that meet those consumer need criteria.
I am a huge fan of Netflix and how they use their data to improve their product and services. Netflix’s data-driven content recommendation is a prime example of when a company employs variuos offensive data strategy tactics. They initially gathered data by renting DVDs and understood what genre users like to watch and what kinds. of actors they like. This process got easier when they started streaming. They harnessed data to personalize content recommendation, and eventually making their own movies and series titles. This ultimately increased their user engagement and retention. This strategy gave them a competitive edge to that of traditional cable TV network providers.
Some lessons that Netflix learned are:
- Personalization enhances user experience and keeps customers engaged;
- Investment in machine learning and analytics is key for understanding user behavior;
- Data-driven decision making can drive business growth;
Defensive Data Strategy
In this approach, the primary goal is to protect and secure data. It focuses on compliance, data privacy, and minimizing risks associated with data breaches. Industries like healthcare and finance often adopt this strategy due to stringent regulations.
Compliance and Data Privacy
Any organization that deals with some sort of user data has to employ defensive strategies to comply with data privacy and protection laws such as GDPR, HIPPA, PIPEDA, or CCPA. There is a laundry list of criteria for each of these compliance laws which is outside of the scope of this article. However, a good example is that in these situations you should care for how and where user data is stored, accessed, and deleted. For instance, GDPR requires that the data belonging to a users in European Union to be stored on a server in EU or a jurisdiction that abids by European laws.
Risk Management
Data related risks should be identified and mitigated by implementing security measures, encryption, access controls, and data audits. When I worked in cannabis industry we gathered usage data from user’s vaporizers. A common risk we had to deal with was to how store the user behavior data on our data warehouse so that nobody could decipher it back to the user, and only user had the control over their actual data. The approach was to use a special kind of encryption that user controls its key of. We stored all the data anonimized and still could use it to study user behavior and create personalized features, but ony user can see and attribute the raw data to themselves. And when the user requested data deletion, all of their data in our data warehouse would become orphaned.
Incident Response
It is important as part of a defensive data strategy, to develop clear protocols and response plans for data breaches or security incidents to minimize potential damage. I believe every organization needs an incident response plan once they store any user data that can be abused.
Because in the sharing economy, trust is paramount, Airbnb employs a defensive data strategy to ensure safety and privacy of its users. They use data to identify indentities, monitor user reviews, and detect fraudulent listings. In addition, they comply with regulations and data privacy laws in various countries, earning the trust of their hosts and guests.
Some lessons learned from Airbnb’s story are:
- Trust and data security are crutial for marketplace platforms;
- Compliance with local data protection regulations is vital;
- Data-driven security measures can prevent fraud and build trust;
Enterprise Data Strategy
In my opinion, enterprise data strategy is another term for simply data strategy but bloated with the term “enterprise” because big fortune 500s like to call themselves enterprises, but really there is not that much difference in having a solid data strategy. In a nutshell, this is a comprehensive framework designed to ensure that an organization’s data-related initiatives are aligned with its overall business objectives. Unified methodologies are used to collect, manage, and process data across the entire organization while maintaining data governance and security.
In some organizations defining an enterprise data strategy would require a lot of leg work across different organizations, hence some like to hire a Chief Information Officer to be responsible for this.
Implementing a Successful Data Strategy
We discussed earlier that a robust data strategy can drive business growth, enhance decision-making, and ensure a competitive edge for the long term. With this being our goal, we can gauge on effectiveness of our data strategy throughout the lifecycle of our product and business development. Here is a basic plan on how to come up with a data strategy:
Define Clear Objectives
Whether we want to improve customer satisfaction, increase revenue, or optimize operation’s cost, we need a prioritized list of our goals first.
Data Governance
Some may delay or omit this item from their plans, but from my experience it is essential to have a sense of a governance framework early on because it is going to be magnitudes more difficult and time consuming to do this once there are large amounts of data has already been collected. For example, if you never thought about how to cleanup user identifiable information from the data you collected from user activity in your data warehouse, you will not be compliant with policies like GDPR, or CCPA, increasing your risk of lawsuit.
Invest in Data Quality
This is likely the most critical aspect of any data strategy implementation. A report by IDC (International Data Corporation), states that companies lose 20-30% of their revenue due to poor data quality. This speaks to the scale of inefficiency and rework.
Adopt Advanced Analytics
Say goodbye to spreadsheets (sorry finance people, I can do everything in BI), and employ advanced BI tools such as Tableu, Looker, Superset, of PowerBI.
Data Culture
It is time to say goodbye to your experience, and gut feelings. Everyone in an organization should value data, and have the data to support their arguments. Make this culture hard, and don’t let anyone slide by it.
Continuous Evaluation
Japanese coined a term for this called Kaizen. Like anything that human invented going obsolete at some point, you must keep an eye on latest trends and technologies to stay on the edge with your data strategy.
If you like to read more about a real world scenario of a data strategy for a business, read my other article “Implementing Effective Data Strategy – A Cannabis Company’s Journey”.