In this article I’ll describe the journey to architect and build a web scale image service. This could be the way some very large services like Pinterest, and Instagram host and serve their images.
Recall the previous article where we discussed scaling a sharded image service in a data center? We walked away with a solution that was low risk as time was our limiting factor in our decision. However, it really didn’t solve the core architectural problems. The solution was not at web scale. Let’s review those problems:
- Not Durable: the durability of storage didn’t exists beside the copies of images in the single data center.
- Not Performant: the performance of the service would only be good enough to service north America regions and not elsewhere. Moreover, the performance depends on availability of large cache nodes.
- Not Scalable: there is no way to easily setup POPs and scale the infrastructure for global traffic.
- Expensive: operational costs added up quickly.
- Hard to Maintain: we learned from our past exercise that scaling the cluster would take a significant amount of effort. Additionally, the execution time to rebalance the cluster is directly proportional to the size of storage.
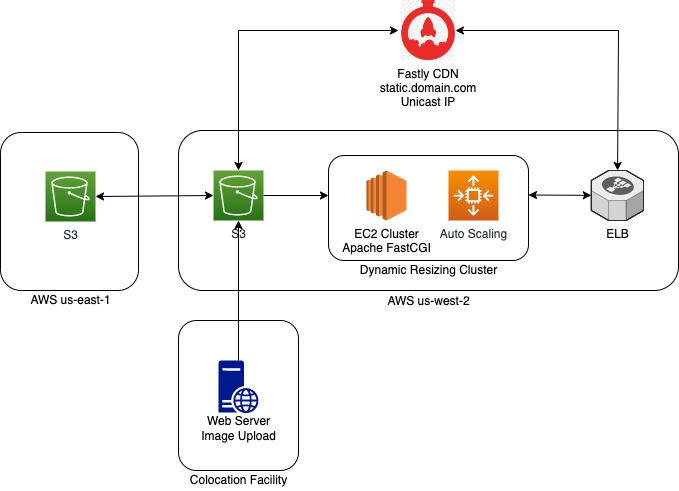
Storage
Amazon S3 is a good choice for storing images in the cloud. It has a durability of 99.999999999% and availability of 99.99%. However, we need to prefix our objects in S3 so that we could achieve the maximum read throughput from S3. Read the following AWS documentation to learn how to organize objects using prefixes.
Since the image files are hashes, we take the first 6 characters for form object prefixes in S3.
2
3
4
/home/images/<strong>3972b1</strong>6287e595a88a50624587bccc66ece0f4c7.jpg
On S3:
s3://my-image-bucket/3972/b1/<strong>3972b1</strong>6287e595a88a50624587bccc66ece0f4c7.jpg
This has a couple of advantages. Because S3 shards the data by prefix, prefixing objects distributes them on different S3 clusters by the first 6 characters of the object. When we have a large cache miss ratio due to caches being cold, the load would not hit a single S3 cluster. Therefore, this solves the thundering herd problem with S3 requests. Additionally, let’s say if we’d want to scan the images in the bucket in a particular range, we don’t have to scan the entire bucket and scanning with prefixes would be a much faster option.
Please note that for any prefix scheme to design, you should file a support request with AWS informing them of your scheme and desired throughput. The AWS team would do some magic in the backend to ensure their service can handle your request with milliseconds latency at that throughput.
Application code was setup to write to both image shards and S3. We also setup a nightly syncing process between image servers and S3. Additionally, we setup a bucket in another region to have a multi-region image storage. Hence, we would have even higher durability and performance in case of a cache miss.
Dynamic Image Resizing
We used Image Magic library with its PHP bindings to write a simple API script that would read the images from S3, perform resizing on the fly and return the output to the cache servers. There are many ways to host this API.
Dynamic Resizing at the Edge with Akamai
We were exploring CDN options to replace Varnish cache. Akamai at the time had launched a solution within their Image Manager product suite that did the image resizing at the edge. We performed several load tests. However, we couldn’t achieve the desired performance in the cache miss scenario. This could be due to several factor involving dynamic routing of Akamai’s SureRoute and where our us-west-2 Oregon origin was relative to Akamai’s POPs. We worked closely with the Akamai team, but the root cause of performance issues was never 100% remedied. So we moved on from testing this solution further.
Host EC2 Instances
One solution would be to host EC2 instances with Apache and PHP FastCGI. This is likely the classic solution of hosting machines with auto-scaling to run the API code. Additionally, our existing configuration management already had packages to setup this machine role, so we were only decoupling the storage to S3 modifying our PHP script tiny bit to read objects from S3.
Load testing this solution revealed desired performance can be achieved in both cold start and warm cache operations.
When we worked on the above solution in summer of 2014, AWS didn’t have the managed Kubernetes service nor Lambda. Ideally even more cost effective solutions could exist. I added these section to this article for better reference of the future evolution of this service.
Kubernetes
At the time of writing this article, Kubernetes had just started to gain momentum in the software community. The team didn’t have any prior experience with running things on K8S, so there is likely a longer time to evaluate this solution and settle with it. We simply skipped this for time constraints.
AWS Lambda
AWS Lambda was released on November of 2014, just 2 months after we launched the solution with EC2. The simplest way to host this API in a server-less fashion is to use API Gateway with Lambda function. This is also the most cost effective way. However, once performing load testing on this solution, the performance can be spotty. This attributed to how Lambda functions are provisioned and persisted in AWS. We had the request load metrics from our last cold start and warm operation of the image cache. So we could eventually follow some AWS Labmda performance optimization tips to tune the Lambda configuration to have persisted concurrency for cold start scenario before launch and then later tune it down.
This would be the ideal cost effective solution upon prove of performance. It is server-less and has a very low maintenance cost.
CDN Caching
We were running several proof of concepts with different CDN providers starting with Akamai. Since couldn’t beat our baseline performance with Akamai, we knew we had to setup our dynamic resizing solution ourselves as explained above. This opened up the opportunities to explore a wide variety of CDN providers that didn’t have image resizing in their solution. We chose Fastly because our load testing revealed highest performance compared to other CDN providers and we significantly beat our baseline too. Another plus point for using Fastly was its ease of setup. Since its backbone runs on Varnish and we were very familiar with Varnish, it significantly simplified our deployment and we could move several of our Varnish VCLs and security configurations over to Fastly in a breeze.
Load Testing
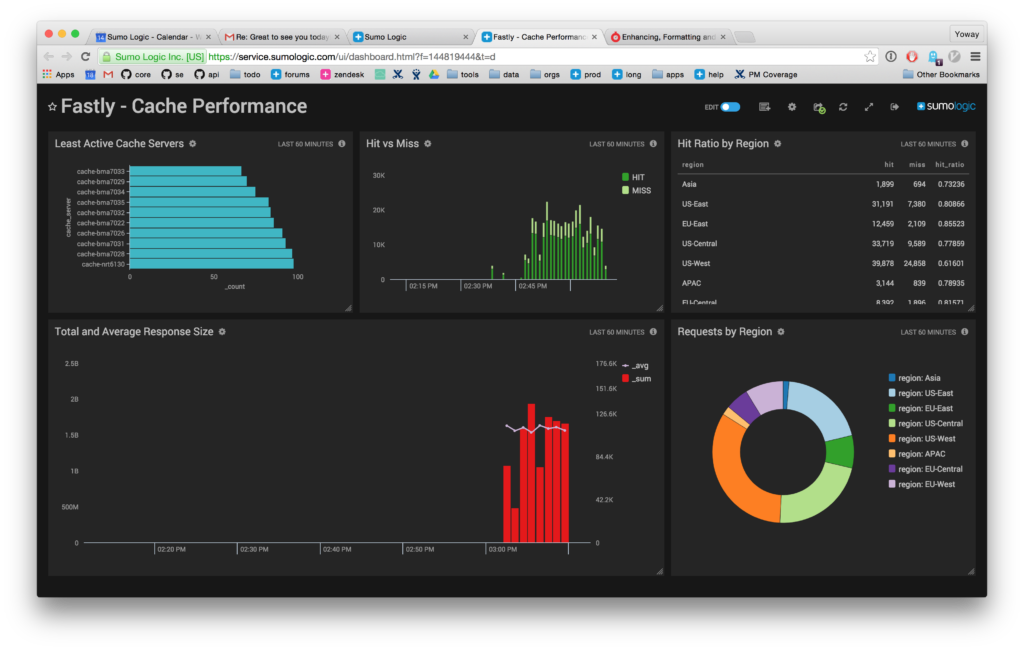
We performed load testing via Apache JMeter. We designed our test plan by downloading a list of image URLs from requests in the server logs. To capture a good range, we took the data for one week. Then used JMeter UI to formulate a test plan. This would save the test plan into XML format. We took the XML as our base test plan, and since the CDN domain was parametrized, we could simply switch it in place via a script. A CloudFormation stack would spin up EC2 instances in various AWS regions to simulate live traffic from multiple locations. In the EC2 instance’s startup user script we made all the changes we need to the XML and fired up JMeter to run its test and then uploaded the resulting JTL files to S3. Later we used JMeter and loaded the JTL files and looked at the plots to get average, and standard deviations for request latencies. At the same time, we monitors cache warmup by looking at metrics like hit ratio.
Launch Plan
The cutover plan to this new image service was straightforward. To pre-warm the cache, we setup a worker that listened to existing infrastructure’s requests, and fired up a new request to the CDN URL. This means that in the background we mirrored live traffic against CDN. This helps with warming up LRU cache in Fastly Varnish as more requests sent to the same image, would make it persist in cache memory. Once our cache hit ratio was above 80%, we decided it is a good time to cut over, and in the span of a week after cutover, we were able to achieve 92+% cache hit ratio from Fastly which was excellent. Our cache misses at max had the latency of 150ms, and cache hits were served all under 20ms.
User Experience Impact
The user experience was impacted as part of this transition. We noticed 15% uplift in DAUs and active session length. This speaks to the long term belief that performance does impact user experience indeed.
Conclusion
In conclusion our new solution resolved all of the outstanding pain points in this service architecture. We achieved durability by using S3. We setup multi-region S3 syncing in case we wanted to have multi-region availability later on. Our infrastructure cost for image service was reduced to fraction of the bills we used to pay for renting servers and paying for bandwidth in various data centers. It scales seamlessly without needing manual intervention of a human. Overall, we built a web scale image service that is tolerant, performant, and lasts for good.